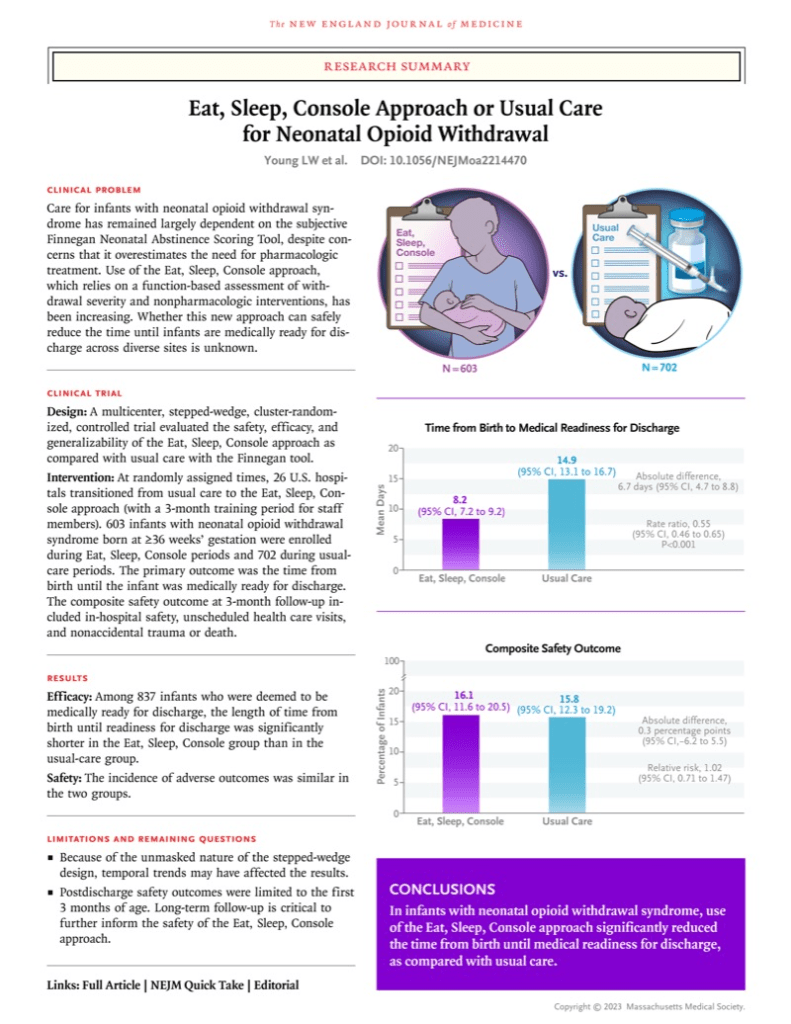
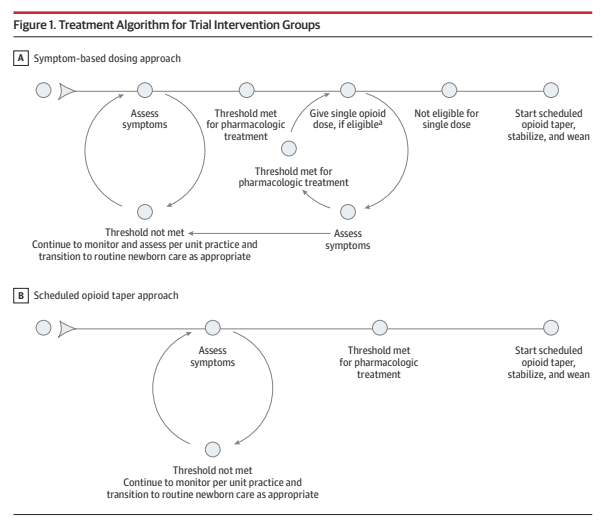
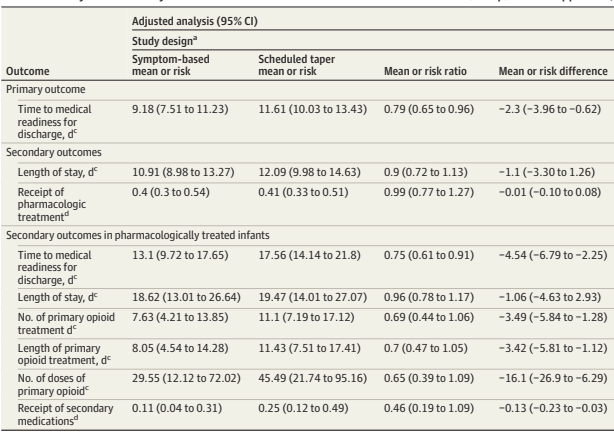
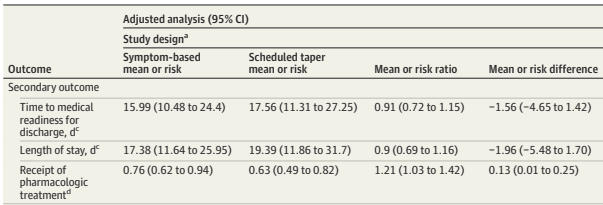
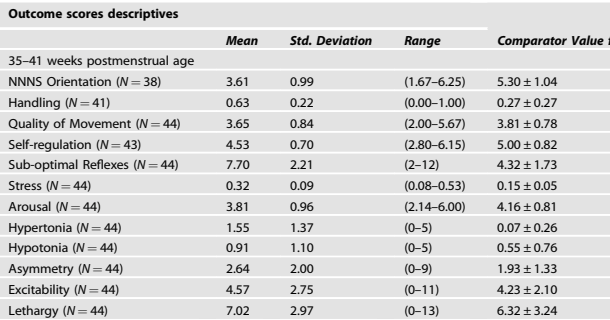
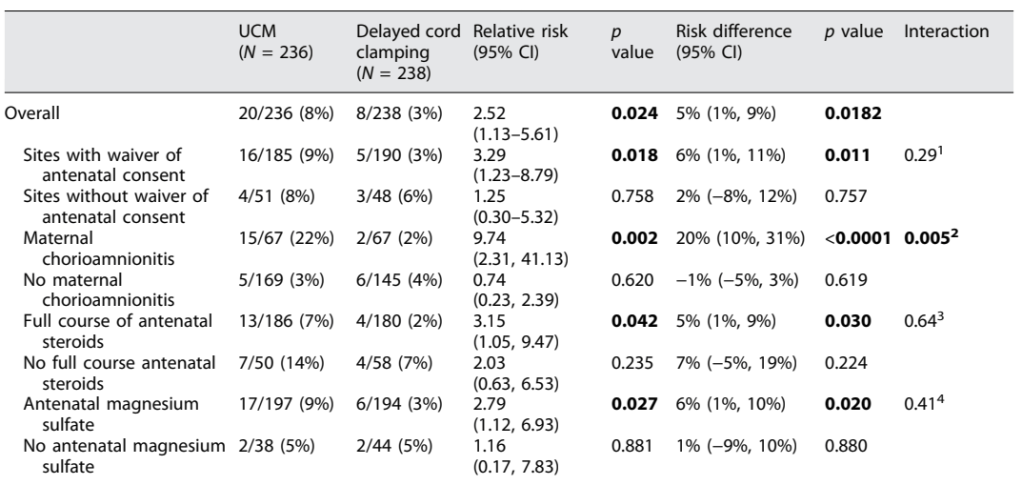
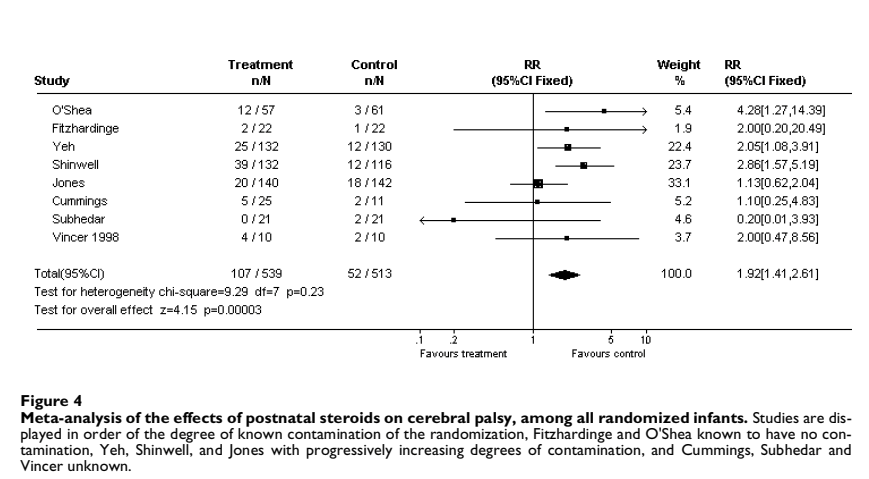
One of the thorniest topics in neonatology currently. Some experts seem certain that we can define PDAs that benefit from early treatment. In contrast, the recent trials don’t show any clinical benefit in early treated groups compared to controls, and indeed usually show an increase in BPD with early treatment, and an increase in mortality with very early treatment. I have posted many times over the last few years about trials of PDA closure. See here https://neonatalresearch.org/2022/12/21/the-pda-will-we-ever-know-what-to-do/ and here https://neonatalresearch.org/2023/10/20/closing-the-pda-or-leaving-it-alone/ and here https://neonatalresearch.org/2024/01/26/is-there-any-indication-to-close-the-pda/ and here https://neonatalresearch.org/2025/12/10/should-we-ever-close-the-pda/.
Bedside echocardiography has been used to try and define characteristics of the baby and the ductus that might benefit from treatment, but the difficulties in interpretation mean that most of the trials have either just confirmed patency, or have just measured ductus diameter (which isn’t much above the limits of resolution of the devices) as a criterion for entry into the trial.
Studies of the natural history of the PDA in the very immature infant confirm that, sometimes, large diameter PDAs close spontaneously, whereas other PDAs of similar size may have large shunts and tend to remain open. If we could be smarter about this, maybe we could define criteria for a study which would only include those where the shunt is causing problems, the PDA will tend to stay open, and it really is contributing to the adverse outcomes of the baby.
The latest attempt to do so is the SMART-PDA trial recently published in Archives Mitra S, et al. Selective early medical treatment of the patent ductus arteriosus in extremely low gestational age infants: a pilot randomised controlled trial (SMART-PDA). Arch Dis Child Fetal Neonatal Ed. 2026. The protocol for this pilot was previously published, and the diagram below is taken from that prior publication
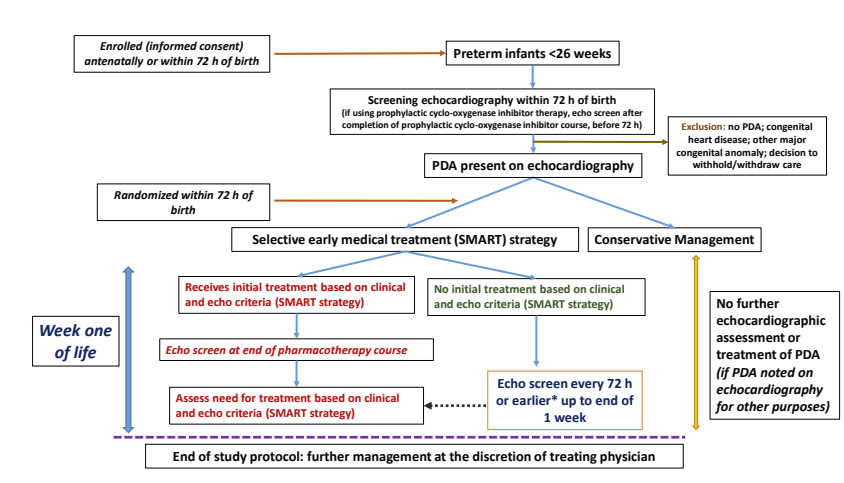
The trial was performed in 4 Canadian and 3 US NICUs with functional echocardiography programs. It only included infants with a GA of <26 weeks. Of note, the trial lasted until day 7 of life. after which open label treatment of control group (or indeed active treatment group) infants was permitted.
Eligibility for the trial required an open PDA, documented prior to 72 hours of age, after which treatment in the active treatment arm followed an algorithm, requiring at least a “moderate” shunt, with “moderate” or severe clinical signs, or a “severe” shunt as defined in the right-hand column below, regardless of clinical status.

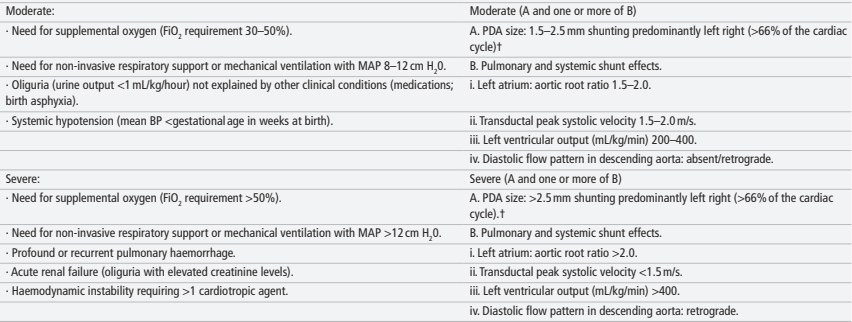
This trial was designed and powered as a pilot, with the primary outcome being the feasibility of a future adequately powered trial, feasibility being determined by the following “The proportion of eligible infants recruited during the study period, (2) the proportion of treatment outside of protocol-mandated therapy among randomised infants and (3) the proportion of infants in the control group meeting pre-defined safety criteria.” Sample size was also determined by feasibility considerations and required 100 randomized infants.
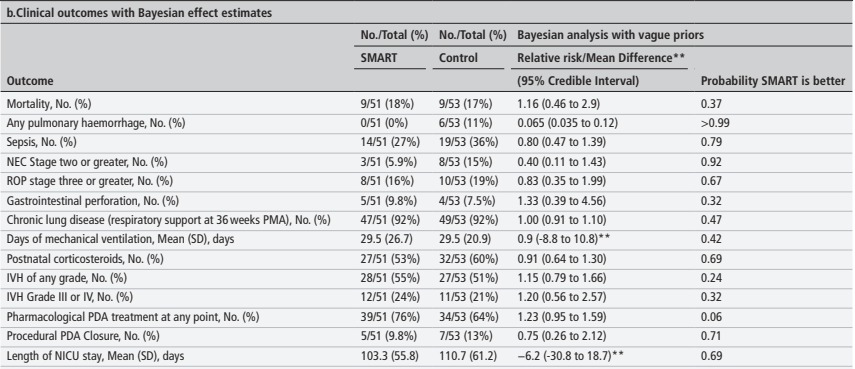
The usual clinical outcomes were collected and analyzed using Bayesian methods, and a WinRatio hierarchical composite was constructed (not mentioned in the protocol).
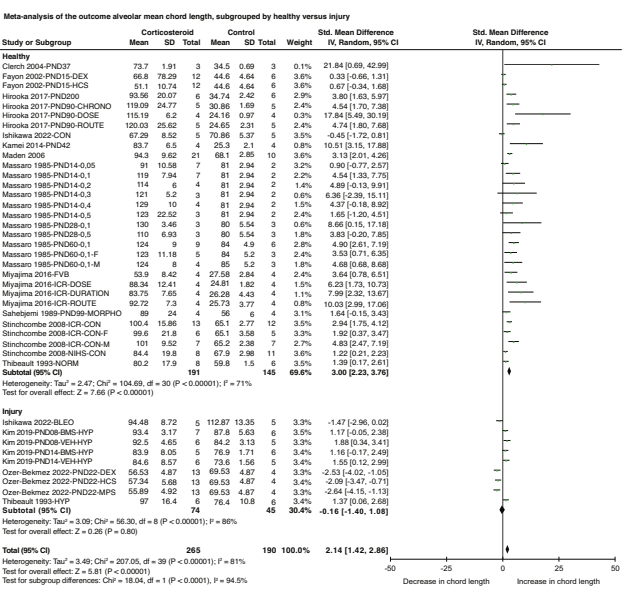
As a moderately sized trial there were some small imbalances in baseline characteristics, more of the controls were 24 weeks or less, more controls had normal antegrade descending aortic flow, etc. but generally speaking the groups were quite balanced.
The feasibility outcomes all demonstrated that a future trial is entirely feasible, with a high recruitment rate, and only 1 control was a protocol violation and was treated to close the PDA before 7 days of age.
In terms of clinical outcomes there were 2 differences that stand out, the most striking being the reduction in pulmonary haemorrhage in the active treatment arm, 0/51 compared to 6/53, 11%; also NEC was 6% compared to 15%.
These data were also analyzed using a Win Ratio approach, with the outcomes of Death, Pulmonary haemorrhage, sepsis, NEC or RoP. If you don’t recall what that means, basically every individual baby in the SMART group was compared with every individual in the CONTROL group, and for each comparison a decision is made whether the SMART group infant is a winner (has better outcomes) or a loser, or if there is a tie. So for example if baby 1SMART and baby 52CONTROL both survive and neither have a pulmonary haemorrhage, but baby 52CONTROL has sepsis and baby 1SMART does not, then baby 1SMART is the winner. Finally you add up all the wins and the losses, and the ratio of wins to losses is calculated. The analysis in this paper then applies a Bayesian approach, which shows that SMART has a higher likelihood of being preferable than control.
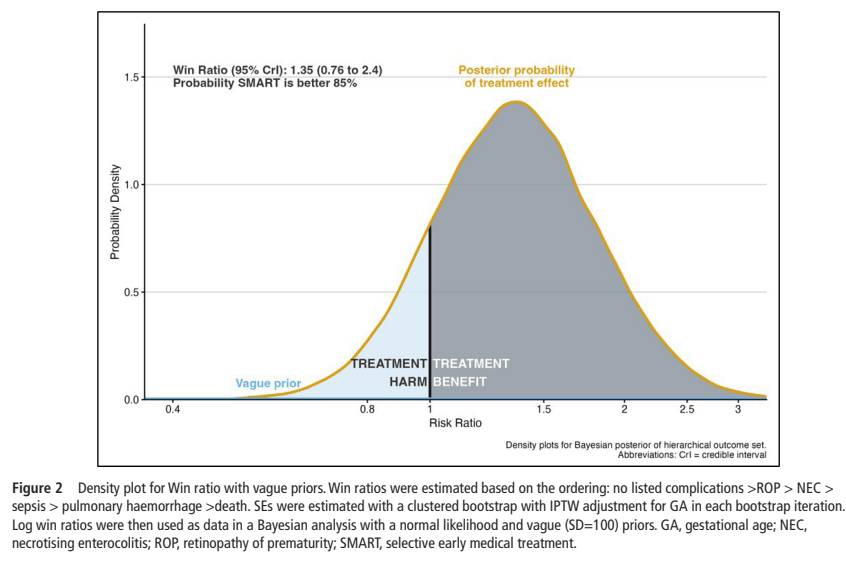
This is a much better approach than just “death or complications” as a binary outcome, as it immediately gives survival a higher importance than the other outcomes, unlike “death or BPD” (for example) which gives them equal weight. It does require some partially subjective decisions, for example I would probably put the outcomes in the following decreasing severity order : septic shock, NEC grade 3, NEC grade 2, culture-positive sepsis without shock. Pulmonary haemorrhage, I certainly agree, is a very important complication, especially as defined here, associated with increased oxygen requirements leading to an MAP >12 and an FiO2 >60%. Putting it as the second most important adverse outcome seems reasonable.
Of note, 16 (/53, 30%) control infants had a “predefined safety event”, which seems to be either a severe pulmonary haemorrhage or persistent hypotension, 4 of them received PDA medications before 7 days to treat those events; a further 29 of the control infants received PDA medications after the 7 days, for a total of 64% of the controls receiving treatment. 35% of the SMART group didn’t satisfy the treatment criteria during the 7 day trial period.
This pilot gives adequate justification for a larger trial, it does not, I think, provide strong enough justification for routine implementation of the SMART protocol. The only significant benefit, an important one, was one of many secondary clinical outcomes, the reduction in pulmonary haemorrhage. Other trials of early PDA closure have also shown fewer pulmonary haemorrhages, in particular Martin Kluckow’s trial of early indomethacin (Kluckow M, et al. A randomised placebo-controlled trial of early treatment of the patent ductus arteriosus. Arch Dis Child Fetal Neonatal Ed. 2014;99(2):F99–F104). In that trial of infants <29 weeks GA, echocardiographic screening was much earlier, 3 to 12 hours of age, and infants were eligible for treatment on the basis of simply PDA diameter, and the absence of bidirectional shunting (diameter limits being >1.8 mm at postnatal age 3–5 h, >1.6 mm at post- natal age 6–8 h and >1.3 mm at postnatal age 9–12 h). The study was stopped early because Indomethacin was no longer available. Early pulmonary haemorrhage was much less frequent with early intervention among those with a large PDA, 1/44 va 10/48. But the primary outcomes, for which that trial was designed, were no different between groups.
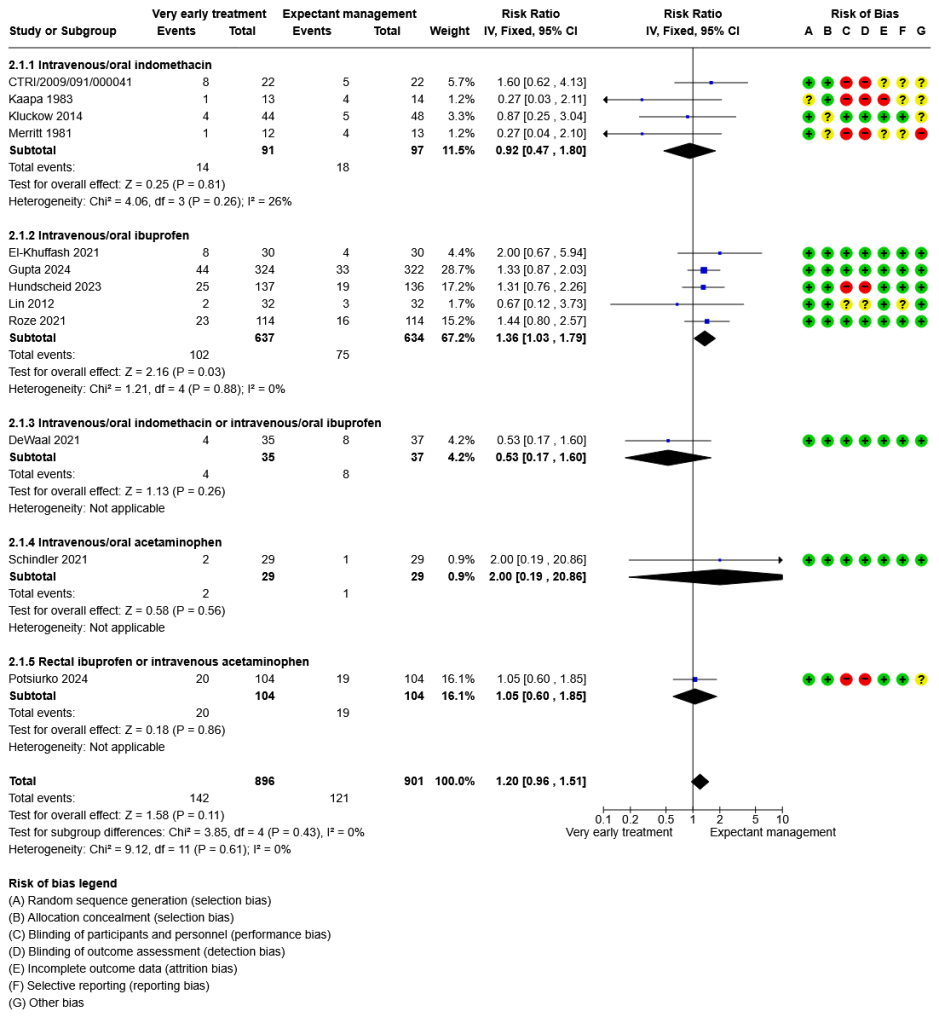
As you can see from this Forest plot from the latest Cochrane review of early PDA treatment, there is an increase in mortality with very early ibuprofen, overall. Any future trial of very early treatment has to be adequately powered to ensure that there is no increase in death with treatment. This new trial had about 18% mortality in each group, so, to be fairly sure there wasn’t an increase in mortality, of about the amount shown in this SR, (about a 36% increase) with reasonable power (80%), a trial of over 400 patients per group is needed.
The risks of serious pulmonary haemorrhage start quite soon after birth, and I understand the logistical problems with randomizing and enrolling infants after a qualifying echocardiogram before the 72 hour limit in SMART-PDA. But to have the most benefit in reducing pulmonary haemorrhage, randomization before 36 hours would be preferable. It is easy for me to say that, as I don’t do functional echocardiography, so I wouldn’t be on the call schedule for urgent echos over the weekend!
This high quality pilot trial points the way to designing a definitive trial of smarter treatment of the PDA in extremely immature infants. Early screening, eligibility based on criteria which show a large shunt and which predict persistent patency of the PDA seems to be the way to go to answer some of the many questions that remain.