
That isn’t a mis-spelling, just a bad attempt to play with the acronym for a good trial; the PENUT trial, just published in the (FP)NEJM. (Juul SE, et al. A Randomized Trial of Erythropoietin for Neuroprotection in Preterm Infants. N Engl J Med. 2020;382(3):233-43). This was a multicenter trial in infants of at least 24 weeks gestation and less than 28, who either received erythropoietin or placebo and were followed to 2 years of age, with a primary outcome of death or major neurological impairment or developmental delay (NIDD). Hence Preterm Erythopoietin NeUroprotection Trial.
The simplest way to state the results is that they showed no effect; mortality was 13% with erythropoietin and 11% with placebo, and NIDD, among survivors who were evaluated, was 11% with Epo and 14% with placebo.
In more detail the intervention was 1000 U/kg iv every 48 h six times; then subcutaneous at 400 U/kg three times a week until 32 weeks 6 days, started within the first 24 hours of life. Controls received placebo injections, iv and then sham injections during the s/c phase, administered behind a blind by a research nurse. between 22 and 26 months of corrected age the babies had a neuro exam, Bayley-3 and MCHAT (autism screening tool).
Here it gets a bit confusing, there were 941 infants enrolled, randomized 1:1. The primary outcome is only available for 741, in what is called in the abstract a “per-protocol” efficacy analysis. Usually, that term is used when you do a secondary analysis, after the initial Intention-To-Treat analysis, and can be quite different from the ITT if there are a lot of protocol violations (which may be for good reasons). If substantial numbers of controls received erythropoietin, or active treatment babies didn’t get the assigned intervention, then an exploratory per-protocol analysis might demonstrate that the lack of difference between groups (as a hypothetical example) was potentially because of protocol violations, and that maybe the physiological impact would be positive if there had been fewer violations. I don’t think that is what they mean here, I think that they performed an ITT analysis (by which I mean that all babies were analysed according to their assigned group), but one which only includes those who had the neurodev evaluation at the right time.
As you can see in the CONSORT flowchart shown below:


21% of the surviving infants were “excluded”, that is the sum of losses to follow-up, a little over 10% in each group, and incomplete exams (3%), and those outside the 22 to 26 month window (about 6%).
The follow-up rate is certainly less than one would like, especially as non-followed babies are not necessarily the same as babies who are followed. (In some cohorts they tend to have worse outcomes, in others they tend to have better outcomes, it seems to depend on the structure of the health care system).
As you can see from this summary slide of the primary and secondary outcomes any differences between groups were fairly small, and it is possible that a higher follow up rate might have shown a difference in severe cerebral palsy, for example, but it is highly unlikely that the primary outcome (death or severe NIDD) would have been different.
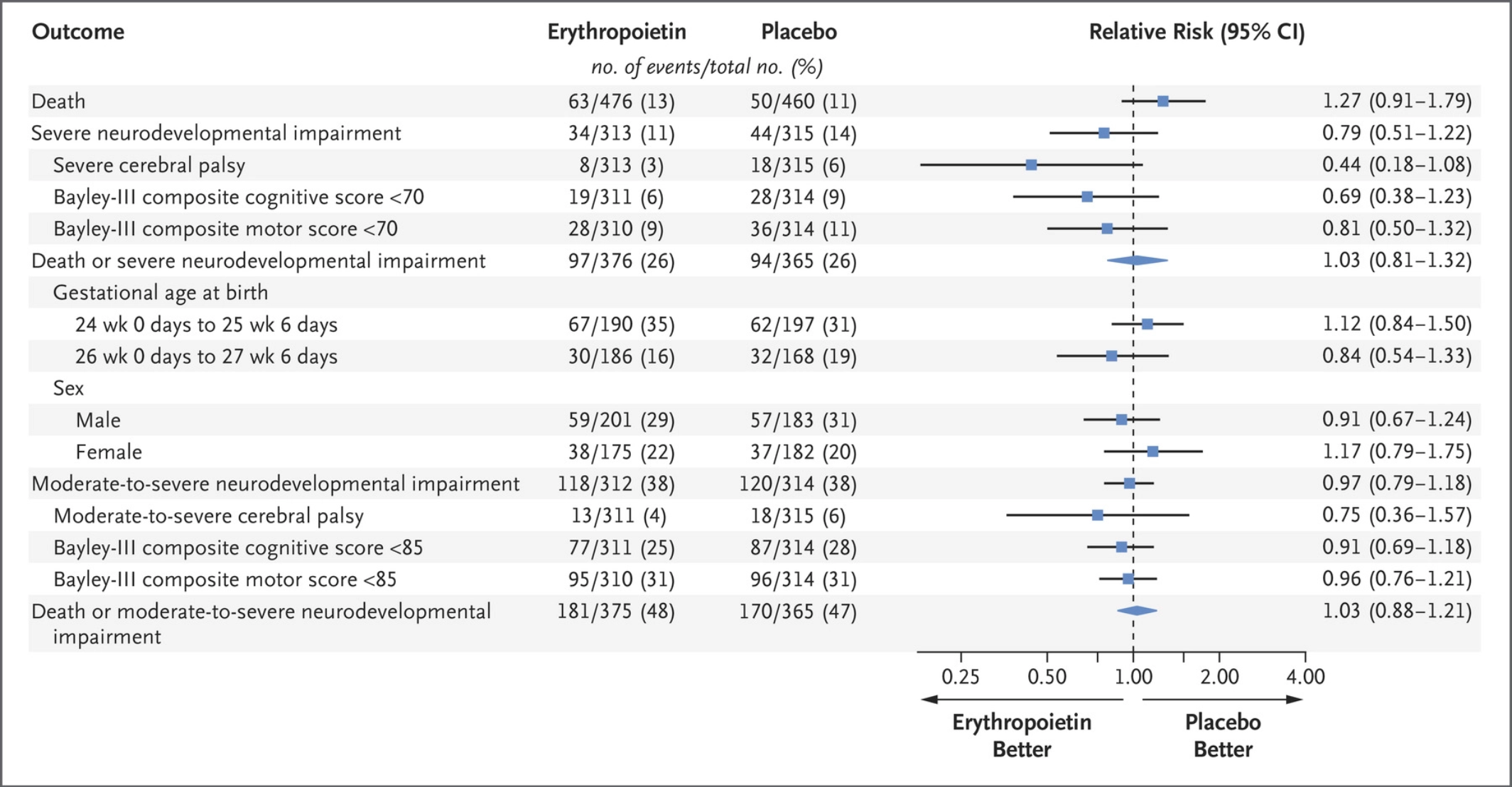
As you can see from this slide the primary outcomes were for severe NIDD, including CP with a GMFCS more than 2, or low results on Bayley-3 cognitive or motor scores below 70. They are described in the text of the paper as being more than 2SD below the mean, but we well know that 70 is not 2 SD below the mean but more like 2.7 SD below the mean of a contemporary group of healthy full-term children.
It is interesting that the rate of Bayley-3 < 70 is lower than most reports for infants of this gestational age, 7.5% low cognitive scores if we put the groups together. The authors explain this by the exclusion criteria having left out the highest risk infants, but I am not sure: as you can see from the flow-chart, only 80 were excluded for “not expected to survive” which is certainly a higher risk group for death or severe NIDD, but the small numbers of other exclusions don’t explain the unusually good Bayley-3 scores. Maybe there is a socio-economic bias among the centres enrolling for this trial, or some other reason, or maybe the 20% not followed would have had worse Bayley scores, or maybe the centres just have good 2 year Bayley outcomes in general, which would be interesting.
In any case, the results are disappointing with regard to Epo, many people were hopeful that Epo therapy would be a partial help in overcoming the disadvantages of being born extremely preterm, the prior smaller studies and systematic review suggested a likely benefit. If you wonder about the dose used in PENUT, then other data provided show that there was at least an erythropoietic effect, active treatment babies were less likely to be transfused and received a lower total volume of transfusion.
The previous systematic review was heavily dependent on the results of Song et al (Song J, et al. Recombinant human erythropoietin improves neurological outcomes in very preterm infants. Ann Neurol. 2016;80(1):24-34). A study from Zhengzhou in China which I missed at the time, probably because it was published in Annals of Neurology, which included 668 babies under 32 weeks, most of whom were over 30 weeks gestation, and most of whom were boys (70%). They had very high rates of PVL (20% among placebo babies), RoP (26%), NEC (14%), Severe IVH (16%), and Sepsis (26%) despite the maturity of the subjects, and the dose was different from PENUT; 500 units/kg every 48 hours x 7 doses. The trial was registered in 2014 after it was performed.
I mention all those details as I think it is clear that the results of the Song et al trial cannot be extrapolated to other jurisdictions with very much lower rates of complications in infants of 30 to 32 weeks gestation. There are also reports of different rates of positive results in trials published coming from different countries, (Vickers A, et al. Do certain countries produce only positive results? A systematic review of controlled trials. Control Clin Trials. 1998;19(2):159-66). That review showed that 100% of published acupuncture trials from China were positive, and 99% of all published trials, of other interventions than acupuncture, from China had positive results. Publication bias may be part of the reason behind this, which is one of the reasons for demanding that all randomized trials be registered before they are started. If they are registered at the same time as analyzing the results or submitting the article there is little point to the exercise, as we will never have any idea which trials were performed, were negative or null, and were never submitted for publication or published.
That review of publication source and potential bias among results is now over 20 years old, has the situation changed? I think those performing systematic reviews need to know. If over 90% of RCTs from a particular source are positive, then within the review a sensitivity analysis excluding studies from that source would be an important part of ensuring the reliability of the results.







Given the nature of CNS development at 24-28 weeks, with immature differentiation, even scaffolding, and connectivity (white matter) and its proposed mechanism of action (Rangarajan & Juul. Pediatric Neurology 51 (2014) 481-488) it is not surprising to me that Epo has less measurable impact than what has been seen in term infants (e.g. HIE).
Pingback: Does erythropoietin prophylaxis prevent NEC? Unreliable data. | Neonatal Research