
The use of continuous EEG has become much more frequent in the NICU in recent years. It has become clear that clinical recognition of seizures, both those with and without clinical convulsions (which I will call electrographic seizures for all identified episodes, convulsions when there are clear motor phenomena, and non-convulsive seizures for those without), is poor. In at-risk infants, with clinical observation alone we fail to diagnose a large proportion of electrographic seizures, as many as 50% of convulsions are not identified, and all non-convulsive seizures. In addition, at-risk infants are often treated with anticonvulsants for episodes which are not electrographic seizures.
Even when prolonged EEG monitoring is used, many seizures are missed, and many babies receive unnecessary anticonvulsants. Even more disheartening, experts reading prolonged EEG often fail to agree about whether an episode is a seizure or not! In one study for example (Stevenson NJ, et al. Interobserver agreement for neonatal seizure detection using multichannel EEG. Ann Clin Transl Neurol. 2015;2(11):1002-11), when seizures were shorter than 30 seconds there was only about 45% agreement between neurologists expert in neonatal EEG interpretation, just under 70% for seizures between 30 and 60 seconds duration, and even over 60 seconds duration agreement was a little less than 90%. There was much more agreement for portions of the record without seizures.
It was that profile of findings that led the group who just published this study (Pavel AM, et al. A machine-learning algorithm for neonatal seizure recognition: a multicentre, randomised, controlled trial. The Lancet Child & Adolescent Health. 2020) to take as their “gold standard” for the presence of electrographic seizures, when 2 experts found seizures and they overlapped for more than 30 seconds. In this randomized controlled study, 264 term babies at risk for seizures either were monitored with regular continuous EEG, using a 9 electrode montage for up to 100 hours, or the same type of EEG hooked up to a PC running a seizure detection algorithm. 25% of the algorithm babies and 29% of the controls were finally classified as having electrographic seizures, which was lower than the pre-trial estimate of 40%, leading to an increase in sample size.
The primary outcome was the diagnostic accuracy of the clinical team in determining the presence of seizures compared between those using the ANSeR system, and those using plain vanilla EEG. Standard EEGs traces were displayed continuously at the bedside, and aEEG traces also. With the new algorithm ANSeR system, there was an audible alarm whenever the seizure probability was over 0.5, and a red line appeared on the EEG trace.
The sample size was calculated based on an increase of 25% in the sensitivity of the clinical team in diagnosing “true” electrographic seizures (i.e. those confirmed by the electrophysiologist experts).
This trial is a rather heroic undertaking, there are so many unknowns that designing such a trial must have been very difficult. There is a big difference between a) diagnosing which babies have had at least one seizure and b) diagnosing each seizure. We might, for example, already, without the algorithm, be relatively efficient at determining which baby has had a seizure, but very poor at counting how many seizures they have had. In fact, that is sort of what they found.
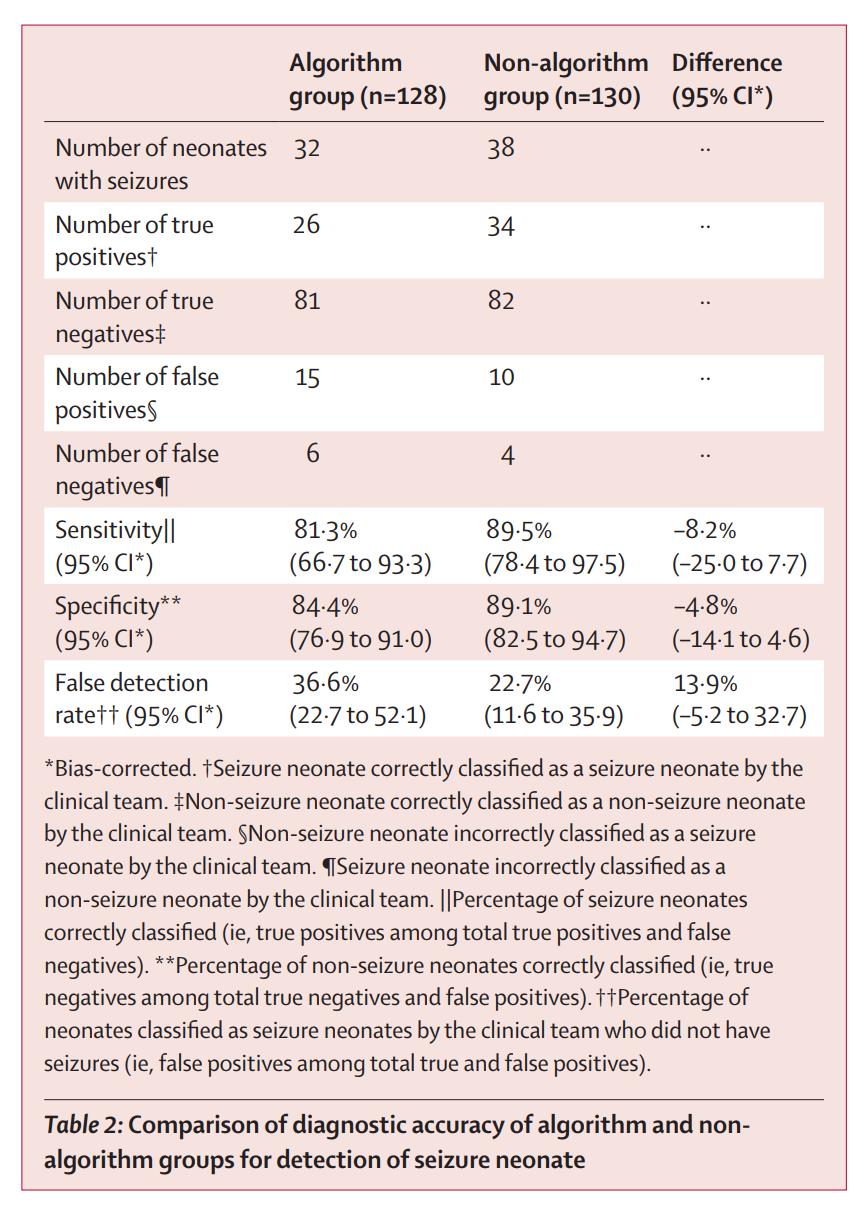
With or without the algorithm, the clinicians identified over 80% of the infants who truly had seizures. With and without the algorithm there were quite a few babies who were thought to have seizures who did not actually have them.
In contrast, when it comes to identifying when a baby is actually having a seizure, the algorithm was clearly better, whether the baby was having a few short seizures, or prolonged or repeated episodes.

Overall, the sensitivity for detection of individual seizures was 66% with the algorithm and 45% without, a difference of 21% (95% intervals 3.6-37%). Some babies in each group who never had a seizure were nevertheless treated with an anticonvulsant (10% vs 4%).
The authors also noted that the algorithm had a bigger impact at weekends compared to weekdays. 17% improvement in seizure detection on weekdays, and a 37% difference during the weekend.
This certainly looks more useful than previous seizure detection algorithms which are used in newborns but were initially designed for adults. According to a statement in the “research in context” box, the ANSeR system did not lead to more anticonvulsants being given, but I can’t find anything in the results about that. They note that there were some babies in each group who received seizure medication they may not have needed.
No significant differences were found between the groups regarding the secondary outcomes of seizure characteristics (total seizure burden, maximum hourly seizure burden, and median seizure duration) and percentage of neonates with seizures given at least one inappropriate antiseizure medication (37·5% [95% CI 25·0 to 56·3] vs 31·6% [21·1 to 47·4]; difference 5·9% [–14·0 to 26·3]).
I was hoping that this trial would show that the ANSeR system would efficiently discriminate between infants with and without seizures, allowing much better targetting of anticonvulsants. Unfortunately, that did not happen. It does, on the other hand, allow much better detection of individual episodes. Widespread use of the system would likely, therefore, lead to more seizures being appropriately detected. I presume there will be a publication about how the administration of anticonvulsants was affected, in much more detail than just the proportion of babies who received drugs they did not necessarily need. It would interesting to see whether doses were escalated, and second anticonvulsants added, more appropriately in the algorithm group than the controls. Whether the use of this system will lead to better long term outcomes remains to be seen, but is apparently being investigated by follow up of this cohort.






